

Inside this Article
How Your Website Builder Choice Affects SEO1. Wix: Best SEO Website Builder for Beginners2. Squarespace: Best for Effective SEO Website Design3. SITE123: Best SEO Site Audit Tool for Small Businesses4. Webador: The Simplest SEO Builder for Mobile Optimization5. Hostinger Website Builder: Top-Tier AI Tools for SEO6. Shopify: The Best E-Commerce PlatformOther Notable Website Builders for SEOOur Additional Tips for Stronger SEO ResultsChoosing the Best Website Builder for SEO SuccessFAQ
Short on Time? These Are the Best Website Builders for SEO in 2025
- Wix – Offers a variety of SEO apps, advanced analytics, and a powerful SEO AI wizard.
- Squarespace – Provides a comprehensive marketing suite, SEO assistance, and advanced analytics.
- SITE123 – Known for its fast loading speeds and user-friendly SEO tools.
How Your Website Builder Choice Affects SEO
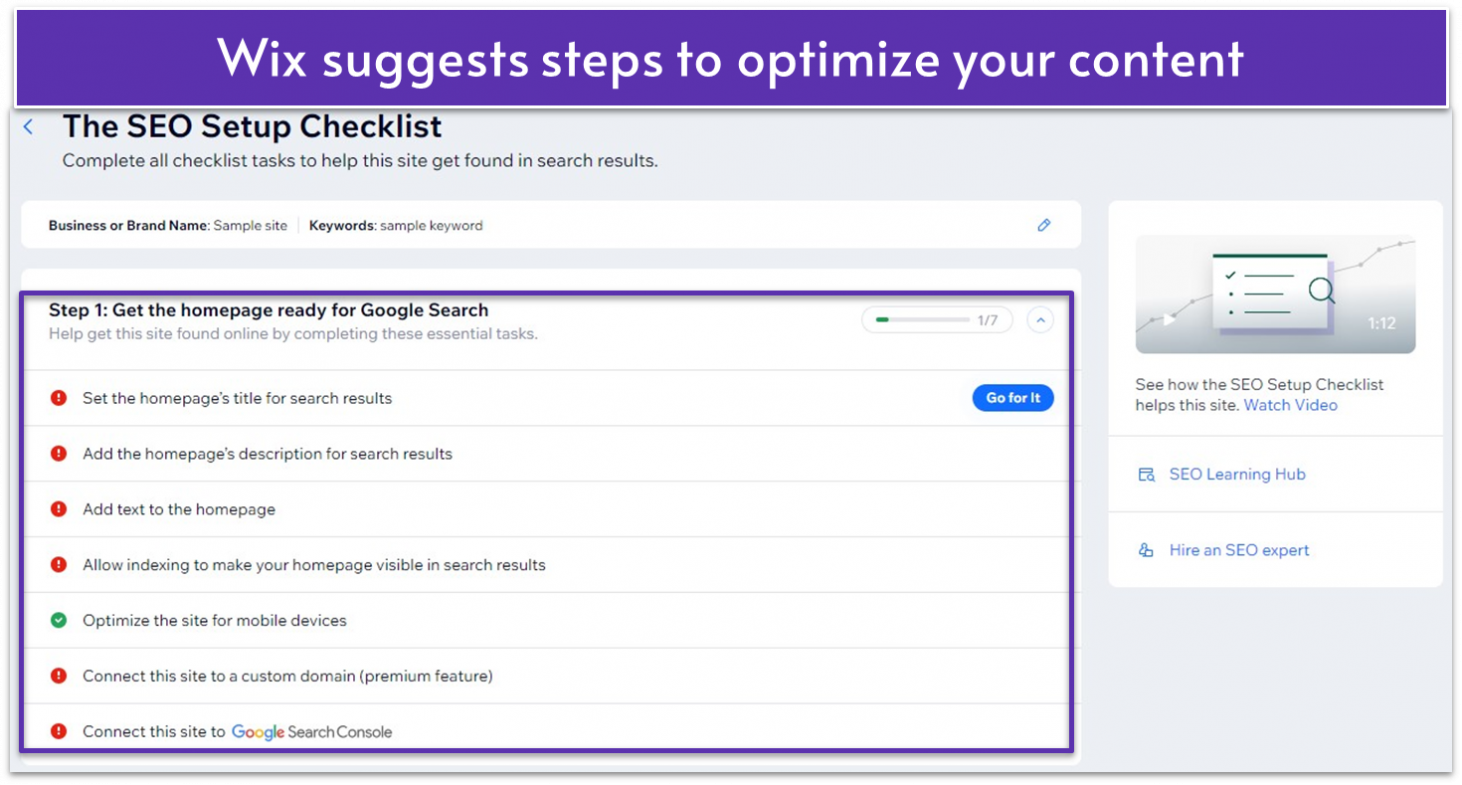
SEO is not just about keywords and backlinks. It’s also about how your website is built and functions. The builder you select can significantly impact how well your website ranks on search engines in various ways, including:- On-page and technical SEO tools. The best website builders offer built-in SEO tools such as automatic sitemap generation, SEO audits, and canonical tags. They allow you to modify page titles and descriptions and structure URLs so search engines understand the hierarchy of your content.
- Site performance. Fast-loading builders that support caching, content delivery network (CDN) integration, and image optimization help reduce load times and improve user experience. This can also give you better Core Web Vitals scores, which affect how your pages rank on Google.
- Apps & plugins. Builders that integrate with tools like Yoast SEO, Semrush, or Google Analytics give you better control and insights into your SEO performance. These integrations allow you to track keywords, analyze traffic, and optimize content effectively.
- Mobile-first approach. Google’s mobile-first indexing means that the mobile version of your site is now the primary version considered by search engines. Your chosen builder should have responsive template designs and allow you to preview and edit the mobile version of your site.
- Content delivery. Builders with strong content management systems (CMS) enable easy blogging, content categorization, and internal linking. These features improve SEO and user experience by making content easily discoverable.
Save up to 50 % on your Wix plan!
Sign up for an annual plan and enjoy the savings.
Plus get a free custom domain for 1 year!
274 users used this coupon!
Features
- AI-powered site creation. Wix’s AI Builder leverages artificial intelligence to design tailored websites for your business. It ensures your site structure and content are optimized for SEO, enhancing your site’s visibility and ranking.
- E-commerce and marketing features. Wix supports robust e-commerce capabilities and integrated marketing tools.
- Detailed SEO tutorials and resource center. Access a comprehensive suite of SEO tutorials and resources within Wix. These guides are invaluable for optimizing your site’s content and structure to achieve better search engine rankings.
- Over 500+ apps. Enhance your site’s functionality and SEO potential with Wix’s extensive app market. It has over 500 first- and third-party apps, including countless for boosting your site’s search engine performance.
| Customizable SEO elements | ✔ (meta tags, URL slug, robots.txt, canonical tags) |
| Mobile-responsive templates | ✔ (with a separate mobile editor) |
| Page load speed optimization | ✔ (CDN, image compression, caching) |
| SEO integrations | ✔ (built-in + third-party tools) |
| Automatic schema markup | ✔ |
| Free SSL certificate | ✔ |
| Built-in site audit | ✔ |
| Starting Price | $17.00 |
Save up to 36 % on your Squarespace plan today!
Plus get a free domain for one year!
80 users used this coupon!
Features
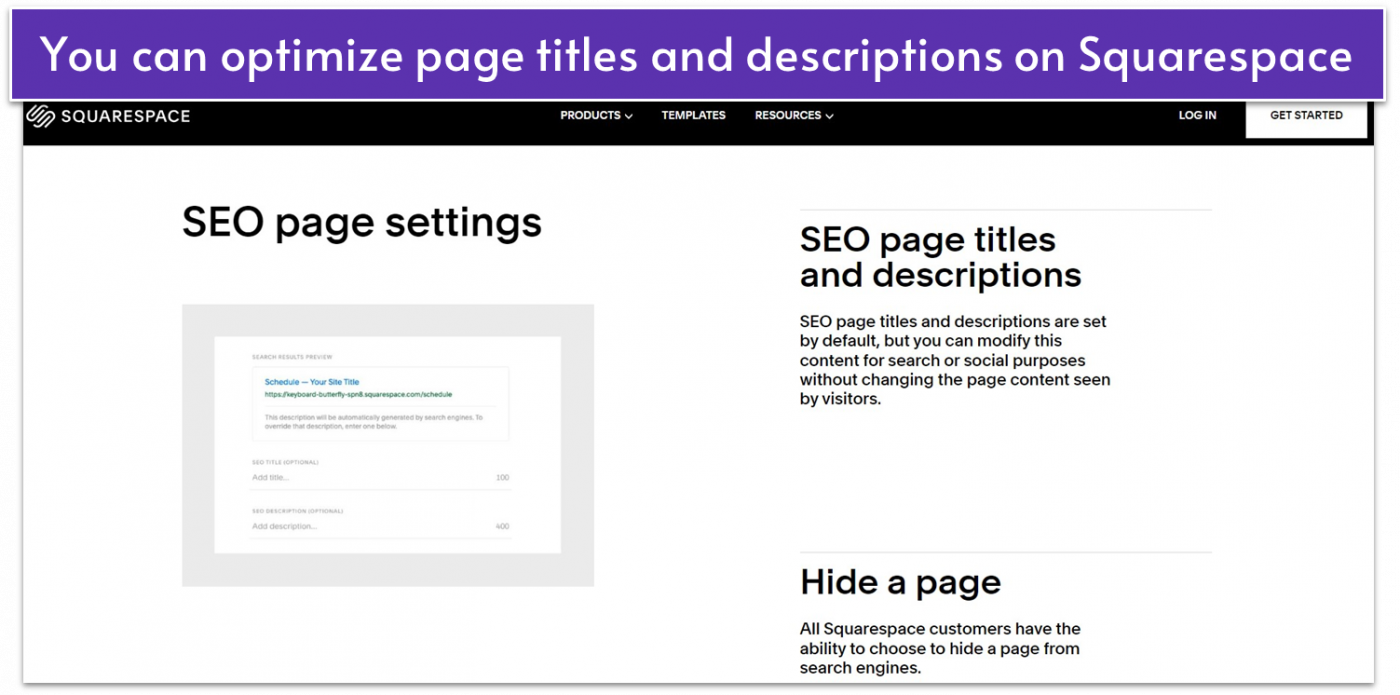
- Professionally-designed templates. Squarespace offers a range of professionally-designed templates that are not only optimized for SEO, but also visually appealing. This ensures that site visitors will stick around on your site once landing on it.
- AMP (accelerated mobile pages) tool. Utilize Squarespace’s AMP tool to create faster-loading mobile blog pages that improve user experience and contribute positively to your site’s SEO performance.
- Squarespace Blueprint. This is Squarespace’s AI design tool. It can help you generate a unique, custom site, plus SEO-friendly text to fill your site with.
- Useful third-party integrations. Squarespace supports a variety of third-party integrations that enhance your site’s functionality and online presence, from analytics tools to advanced marketing solutions.
| Customizable SEO elements | ✔ (meta tags, URL slug, image alt text, code injection) |
| Mobile-responsive templates | ✔ |
| Page load speed optimization | ✔ (CDN) |
| SEO integrations | ✔ (built-in + third-party tools) |
| Automatic schema markup | ✔ |
| Free SSL certificate | ✔ |
| Built-in site audit | ✘ (only traffic and keyword analysis) |
| Starting Price | $16.00 |

Short on time?
Take this one-minute quiz to learn which website builders are best for your project.
Get 40 % OFF SITE123
Save 40 % when you sign up for SITE123's annual plan
225 users used this coupon!
Features
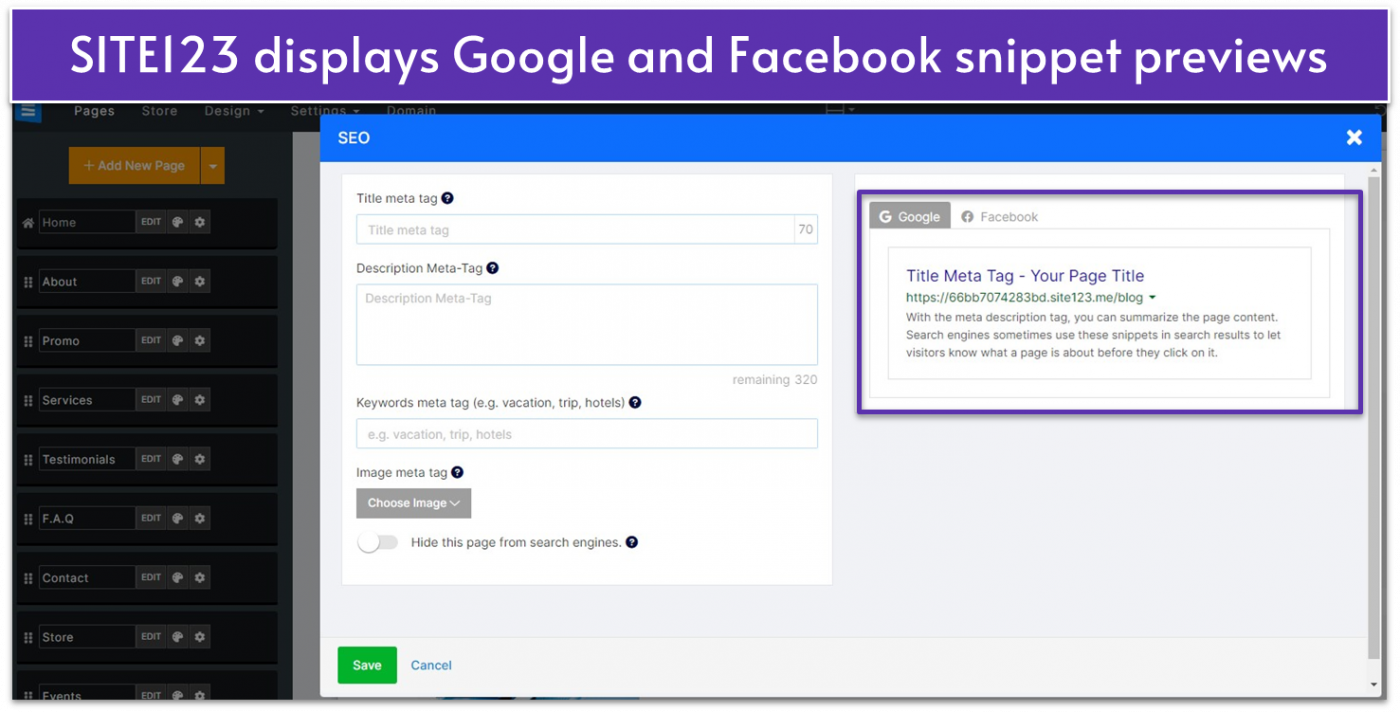
- Multi-language support. SITE123 lets you automatically translate your pages to different languages, which is great for hitting search results in different languages. Plus, each translated page gets its own URL, which is excellent for SEO.
- Basic e-commerce. SITE123 has essential e-commerce tools that help you set up an online store quickly and efficiently. It also has a conversion tracker tool that lets you see which website visits result in purchases, so your SEO efforts are put to good use.
- 24/7 customer support. With round-the-clock customer support in English, SITE123 ensures that you have constant assistance for any SEO queries or website issues, helping maintain your site’s optimal performance.
- Logo Maker. Utilize SITE123’s Logo Maker to create unique, memorable logos that can be easily integrated into your site, boosting brand recognition and complementing your search engine marketing effort.
| Customizable SEO elements | ✔ (meta tags, URL slug) |
| Mobile-responsive templates | ✔ |
| Page load speed optimization | ✔ (CDN) |
| SEO integrations | ✔ (built-in + third-party tools) |
| Automatic schema markup | ✔ |
| Free SSL certificate | ✔ |
| Built-in site audit | ✔ (but limited to on-page SEO) |
| Starting Price | $12.80 |
Features
- Unique widgets. You can upload and display documents using the file-sharing widget. Plus, you can add a five-star rating widget anywhere on the page, so site visitors can rate your blog posts or products.
- Simple blogging tools. You can integrate social media sharing buttons, users can quickly comment on your blog posts so you keep in touch with your audience, and more.
- Collaborative editing. This feature allows multiple users to edit and optimize site content simultaneously. This is especially handy if you’re hiring freelancers or staff to help out with your site’s SEO.
- Free stock photos. Access a library of over 10,000 free stock images, perfect for your web content and SEO.
| Customizable SEO elements | ✔ (meta tags) |
| Mobile-responsive templates | ✔ |
| Page load speed optimization | ✔ (CDN) |
| SEO integrations | ✘ |
| Automatic schema markup | ✘ |
| Free SSL certificate | ✔ |
| Built-in site audit | ✘ |
| Starting Price | $5.00 |
5. Hostinger Website Builder: Top-Tier AI Tools for SEO
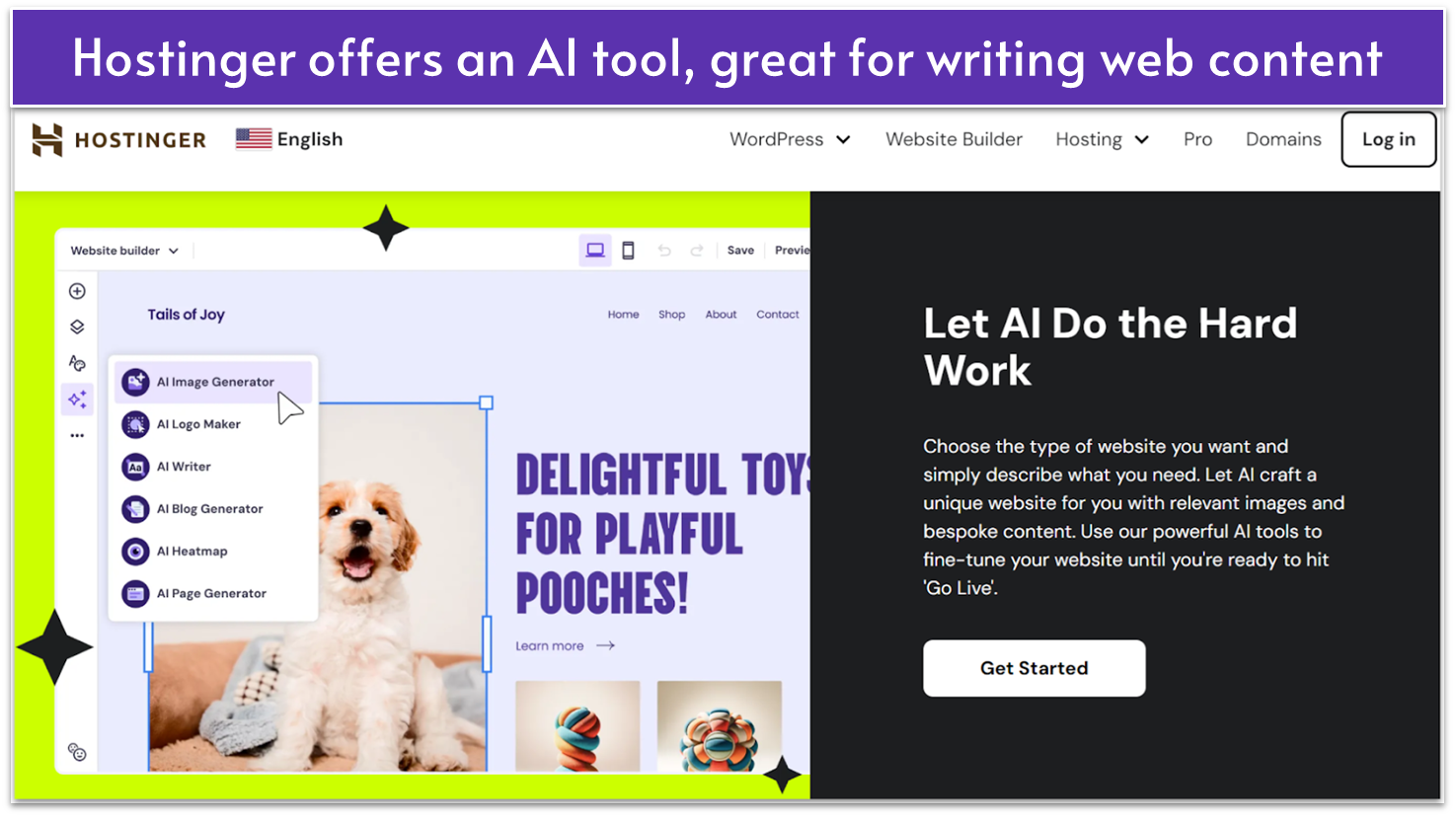
Features
- AI SEO Assistant. Helps automate SEO tasks, generates SEO-friendly content, and comes with a real-time grammar checking and tone adjustments feature.
- SEO-friendly URLs. You can automatically generate clean and readable URLs that are search-engine friendly.
- Image optimization. Hostinger lets you include alt text for images to enhance visibility in image searches.
- Analytics integration. Offers easy integration with tools like Google Analytics and Facebook Pixel for tracking SEO performance.
| Customizable SEO elements | ✔ (meta tags, URL slug, image alt text) |
| Mobile-responsive templates | ✔ |
| Page load speed optimization | ✔ (CDN, caching, image compressor) |
| SEO integrations | ✔ (third-party tools) |
| Automatic schema markup | ✔ |
| Free SSL certificate | ✔ |
| Built-in site audit | ✔ (AI SEO assistant) |
| Starting Price | $2.99 |
6. Shopify: The Best E-Commerce Platform
Features
- Thousands of third-party templates. Shopify supports thousands of third-party templates, each designed to be SEO-friendly, enhancing your store’s visibility and searchability on major search engines.
- Fraud detector tool. Utilize Shopify’s fraud detector tool to protect your transactions and maintain the integrity of your online presence, indirectly supporting your SEO efforts by ensuring user trust.
- Unlimited products and storage. With unlimited products and storage, Shopify enables you to scale your business without worrying about space constraints, which can positively impact your SEO as your catalog expands.
- Local business listings. Shopify helps enhance your SEO strategy by helping to add your site to local business listings, boosting visibility in local search results and attracting more location-specific web traffic.
| Customizable SEO elements | ✔ (meta tags, URL slug, robots.txt, canonical tags, image alt text) |
| Mobile-responsive templates | ✔ |
| Page load speed optimization | ✔ (CDN) |
| SEO integrations | ✔ (third-party tools) |
| Automatic schema markup | ✔ (included in themes by default but limited) |
| Free SSL certificate | ✔ |
| Built-in site audit | ✘ |
| Starting Price | $29.00 |
Other Notable Website Builders for SEO
7. BigCommerce

8. IONOS

9. WordPress.com

10. Web.com
Our Additional Tips for Stronger SEO Results
Though choosing the right builder and making the most out of its SEO tools can be a huge help, there are some universal steps you can take to ensure better SEO results. Some of them are:- Organize your site. A lot of the builders on this list offer checklists to ensure that every page or element has its appropriate meta descriptions and HTML hierarchy, but if yours doesn’t, then you should take the time to ensure that every element on your site does.
- Optimize your images. There are plenty of free and paid tools that can help you optimize your images, that is, reducing their file size without reducing their quality. This step is incredibly important because it will directly impact your website’s performance.
- Check your performance scores. Using a tool like GT metrix or Google PageSpeed Insights, check that your website delivers good loading speeds. Remember that mobile-first indexing is increasingly popular, so make sure that the mobile version of your site delivers good results.
- Update your website regularly. Search engines really value new content, so the more you leave your site stagnant, the more it will fall in rankings. Even if it’s with a blog post every now and then, make sure that your website remains updated.
- Consider external help. If you aren’t seeing the results you’d like, consider hiring an SEO expert to give you a more detailed look at areas for improvement. It doesn’t have to cost a fortune, you can find amazing freelancers on a platform like Fiverr for cheap.
Choosing the Best Website Builder for SEO Success
It’s not enough for a website builder to let you edit meta text and alt image descriptions. While powerful and varied SEO tools are very important, the way in which each builder optimizes its code can also have an important impact in search engine results. For those who need a balance of user-friendliness and robust SEO features, Wix is the optimal choice. It offers rich SEO tools, on top of extensive customization options, and separate mobile editing, which ensures better site visibility and more creative control. Consider Squarespace for stylish designs with strong SEO functionalities. Plus, its powerful marketing features will also be appealing for anyone looking to grow their audience. SITE123 is perfect for beginners needing straightforward SEO adjustments, or anyone who wants to get a simple site online quickly.Check out this table for a quick comparison of the best website builders for SEO.
| Free Plan | Best Feature | Best For | Starting Price | ||
| Wix | ✔ | Wix SEO Assistant | Those looking for complete creative control | $17.00 | |
| Squarespace | ✘ | Complete marketing suite | Brands looking for professional, SEO-friendly templates | $16.00 | |
| SITE123 | ✔ | SEO audit tool | Creating a simple website quickly | $12.80 | |
| Webador | ✔ | Outstanding performance speeds | Beginners to website building | $5.00 | |
| Hostinger Web Builder | ✘ | AI content writer tool | Those who need to push out lots of SEO-friendly web content | $2.99 | |
| Shopify | ✘ | Robust e-commerce platform | Online stores with big catalogs | $29.00 |















